Research
Current projects
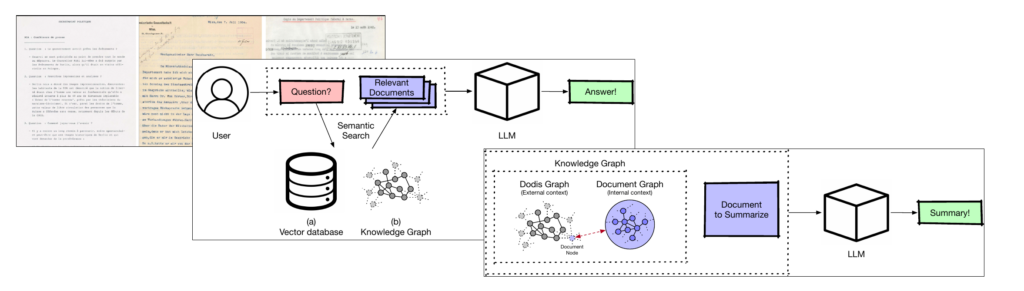
AI-Supported Human-Computer Interaction with Large Volumes of Historical Documents (2025 — 2029)
Abstract: The present project is in the area of computational analysis of documents using machine learning and natural language processing (in particular, large language models} (LLMs)). It is based on a collaboration between the applicants’ research groups and the research center Diplomatic Documents of Switzerland (Dodis), which is the center of excellence for the study of history of Swiss foreign policy. Read More…
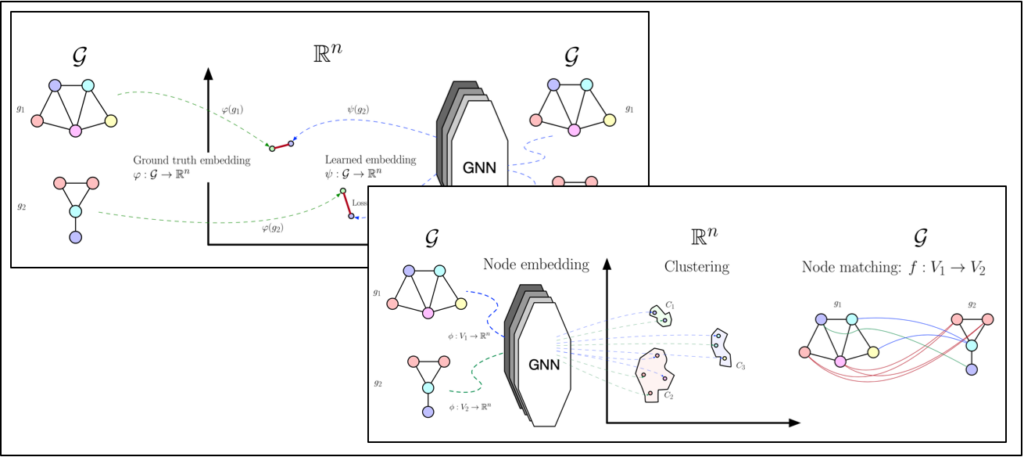
Neural Networks for Learning Graph Embedding and Graph Matching (2024 — 2028)
Abstract: The proposed project is concerned with graph-based pattern recognition. Research in this area can be roughly divided into three time periods, viz. the eras of graph matching, graph kernels, and graph neural networks. The overall objective of the present project is to develop and research robust methods which combine the best ideas and methods that emerged from these three eras. This way, we aim to introduce novel graph-based methods that significantly exceed the current state of the art, both in terms of speed and accuracy. Read More…
A PROSE – Advanced PROofreading SErvices (2022 — 2026)
Abstract: Many proof-reading services are currently focused on orthography, grammar, punctuation, and typography. In these areas, unresolved challenges for automated proofreading exist, comprising detection of so-called real-word errors, compliance with specific typesetting rules and company-specific spelling guidelines, and ensuring the use of gender-neutral language. Further tasks that currently require better solutions are the automatic detection of subjective language and incorrect information (e.g. dates, addresses) in customer documents. Read More…
Spatio-temporal graph convolutional networks – a novel deep learning approach to forecasting river temperatures (2022 — 2026)
Abstract: The Federal Office for the Environment (FOEN) analyses several environmental aspects of Switzerland. The monitoring of water temperatures over long time periods belongs to one of the most important tasks of the Hydrology Division of FOEN. At the moment, the Hydrology Division maintains approximately 80 metering stations. Stations measure various parameters such as water temperature, discharge, water level etc. Read More…
Past Projects
- Novel Paradigms for Machine Learning in Medicine
- Exploring Research Opportunities for Automatic Text Document Summarization
- Novel State-of-the-Art Graph Matching Algorithms
- Knowledge via Graph Reasoning
- 14 Weeks of Java – A Novel Approach for Teaching Java
- Graph Based Signature Verification
- User Authentication based on Freehand Sketches
- Graph Based Keyword Spotting in Handwritten Historical Documents
- Reducing the Overestimation of Graph Edit Distance Approximation
- Improving Graph Edit Distance
- Development of a Graph Matching Toolkit