AI-Supported Human-Computer Interaction with Large Volumes of Historical Documents
| Time | 2025 — 2029 |
| Funding | Swiss National Science Foundation |
| Researchers | Merlin Streilein, Tobias Steiner, Kaspar Riesen |
Abstract: The present project is in the area of computational analysis of documents using machine learning and natural language processing (in particular, large language models} (LLMs)). It is based on a collaboration between the applicants’ research groups and the research center Diplomatic Documents of Switzerland (Dodis), which is the center of excellence for the study of history of Swiss foreign policy.
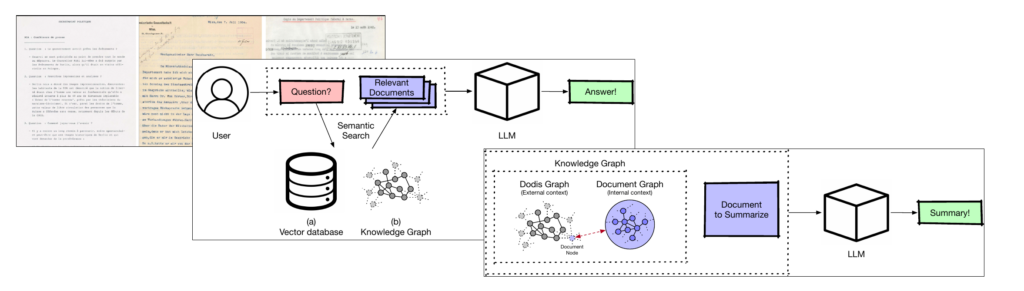
The overarching goal of the project is to research novel algorithms to automate and support the process of studying, understanding, selecting, and editing documents at Dodis. In particular, we strive for a unique solution that allows both experts and interested laypersons to have a written conversation with an artificial system which has in turn access to Dodis’ large document corpus. We aim for a framework that is composed of two building blocks. First, a conversational artificial intelligence (CAI) that accurately answers user questions and follow-up questions and challenges incorrect assumptions, and second a high-quality summarization component that provides accurate and useful summaries of documents avoiding hallucinations.
Both fields of research (i.e., summarization and CAI) gained momentum in the last years and elaborated models are available. However, to further push the boundaries of current understanding and implement a solution that is actually usable for Dodis, substantial efforts in research are required. First, although Dodis will contribute an extensive corpus of real-world documents including ground truth transcripts, we face the major challenge that state-of-the-art OCR is prone to errors for historical typewritten documents and is largely unable to extract (implicit) meta-information from the documents that could be valuable for subsequent research (e.g., the document type or recipient). Second, existing (locally executable) models for summarization produce questionable summaries that are hardly usable for Dodis’ research purposes. Moreover, while public LLMs such as GPT provide grammatically and linguistically sound summaries, the results often do not reflect the historically important aspect of the document (moreover, the summaries are still not precise enough, i.e.~they contain hallucinations). Third, we observe that open platforms like Dodis are based on the idea of keyword search which are not able to answer specific questions in natural language. On the other hand generic CAI platforms provide very vague or even false answers to specific questions on Dodis documents (as they do not have good access to the necessary documents). It is a major research challenge of this project to enable natural language interactions with a novel CAI system based on the large amount of documents available. The aim is to provide highly accurate and verified answers to specific user questions without hallucinations.
We start our research by selecting and preparing large-scale ground truth training sets for building the envisaged systems. We will first research and empirically evaluate existing models for all tasks and systematically document all limitations (e.g., fabricated facts or similar). Major contribution of the present project is then to develop and research novel approaches that use large knowledge graphs to guide and improve both the summarization and CAI processes. In the experimental phase we use both automatic evaluation metrics and human-based evaluations.
The significance and impact of the proposed project is manifold (ranging from unique and novel data sets for document analysis to more robust document workflows using LLMs). One of the most important impacts is, however, that the present project might result in radically different services, which can be interpreted as first –- yet significant — step towards a more natural human-computer interaction with large archives of historical documents.